
Во второй части этой статьи я покажу вам, как был усовершенствован просмотр журнала событий в операционной системе Longhorn Server, как просмотр событий был интегрирован в секцию Troubleshooting section менеджера сервера. В этой статье я подведу итоги этого цикла статей и поговорю о двух оставшихся инструментах, включенных в раздел Troubleshooting (устранение неисправностей) — о менеджере контроля служб (SCM) и утилите для диагностики производительности (Performance Diagnostics utility).
Если вы хотите ознакомиться с остальными частями этой статьи, пожалуйста, прочитайте:
Сразу же под контейнером для просмотра событий в разделе Troubleshooting менеджера сервера располагается контейнер Services (службы). Если вы щелкните левой кнопкой мыши на контейнере Services, то отобразиться окно менеджера управления службами (Service Control Manager) с подробной информацией.
Как вы знаете, менеджер контроля служб не является новинкой в операционной системе Longhorn Server. Он существовал в каждой версии серверной операционной системы Windows. Я не хочу тратить слишком много времени на рассказ о менеджере контроля служб, но скажу лишь, что он основательно изменился по сравнению с операционной системой Windows Server 2003. Однако, я по крайней мере хочу упомянуть, что теперь к менеджеру контроля служб можно получить доступ с помощью раздела устранения неисправностей менеджера сервера.
Гораздо интереснее контейнер Performance Diagnostics (диагностика производительности). Если вы немного работали с операционной системой Windows, то вы без сомнения знакомы с монитором производительности. Монитор производительности является частью диагностики производительности менеджера сервера, но кроме этого в нем есть еще много чего.
Если вы выберите контейнер диагностика производительности, то вы увидите обзор ресурсов, который можно увидеть на рисунке 1. Как вы можете увидеть из рисунка, верхний раздел обзора ресурсов отображает набор графиков, которые показывают использование CPU (процессора), диска (disk), сети (network) и памяти (memory).
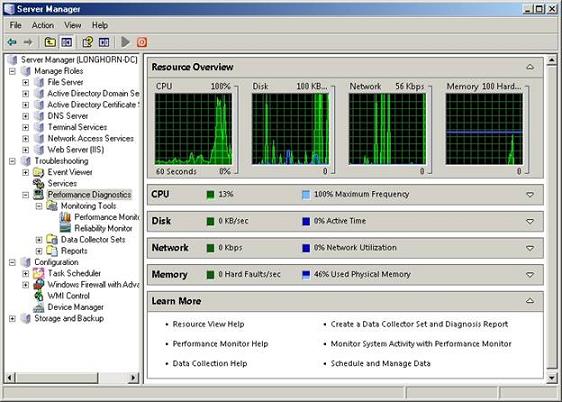
Рисунок 1: Обзор ресурсов графически отображает степень загрузки основных компонентов вашей системы
Если вы посмотрите на рисунок 1, то обратите внимание, то сразу под графиками располагаются отдельные распечатки для процессора, диска, сети и памяти. На первый взгляд может показаться, что эти распечатки необходимы для того, что предоставить вам информацию, которую вы не можете получить, глядя на графики. Однако, если вы посмотрите на правую сторону экрана, то увидите стрелку, направленную вниз, в каждом разделе. Если вы щелкните на эту стрелку, то вы сможете получить гораздо более подробную информацию об использовании каждого из компонентов вашей системы. Например, если вы нажмете на стрелку вниз в разделе CPU, то увидите список всех процессов, которые в настоящее время работают на сервере, а также сколько процессорного времени (CPU time) использует каждый из этих процессов. Аналогично, нажав на стрелку вниз в разделе disk (диск), вы сможете увидеть список процессов, которые обращаются к диску, а также активность на диске, порождаемую каждым из этих процессов.
Если вы вернетесь обратно к дереву консоли и раскроете контейнер Диагностика Производительности, то увидите, что в нем содержится контейнер Monitoring Tools (средства мониторинга). Этот контейнер сам по себе ничего не делает, но он содержит два различных инструмента для мониторинга — Performance Monitor (монитор производительности) и Reliability Monitor (монитор надежности).
Монитор производительности
Я хочу коротко рассказать о мониторе производительности на тот случай, если вы еще с ним не знакомы. Те из вас, кто уже знаком с монитором производительности, могут пропустить это абзац и перейти к следующему параграфу. Монитор производительности не слишком сильно изменился по сравнению с версией в операционной системе Windows Server 2003, кроме его интеграции в менеджер сервера.
Монитор производительности, изображенный на рисунке 2, это утилита для диагностики, которая спроектирована для того, чтобы помочь вам устранить узкие места при устранении неисправностей с вашим аппаратным обеспечением. Если вы посмотрите на нижнюю часть рисунка, то увидите позицию для пометки рядом с полем под названием % Processor Time. Поле % Processor Time показывает общую загрузку процессора за определенные интервалы и отображает ее на графике.
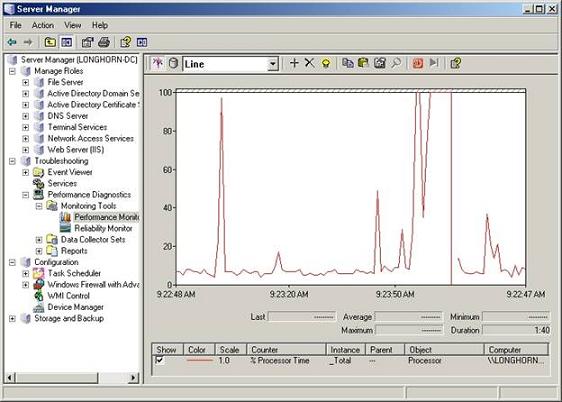
Рисунок 2: Монитор Производительности – это инструмент для диагностики для определения узких мест в аппаратном обеспечении
Параметр % Processor Time — это лишь один из сотни, или даже из тысячи доступных параметров. Каждый параметр спроектирован для измерения определенного аспекта производительности системы. Обычно для каждого из параметров существует пороговое значение, которое отображает проблемы с производительностью. Например, если вы посмотрите на рисунок, то сможете увидеть, есть несколько пиков в работе процессора, во время которых загруженность процессора достигает 100%. Эти пики можно рассматривать, как нормальные, т.к. средняя загрузка процессора после этих пиков, относительно невысокая. Если средняя загруженность процессора постоянно была бы более 80%, то значит, что процессор не справляется со своей задачей и является узким местом в производительности системы.
Я не хочу слишком глубоко погружаться в науку мониторинга производительности, я лишь хочу рассказать о мониторе производительности для тех, кто не использовал его ранее.
Монитор надежности
Последнее, о чем я хочу рассказать вам, это монитор. Монитор надежности (Reliability Monitor) – это великолепный инструмент для тех людей, которым иногда приходиться работать с незнакомыми системами. Например, вы работаете консультантом, и клиент вызывает вас для того, чтобы вы устранили проблему на его сервере, тогда первый вопрос, который вы зададите клиенту, вероятно, будет связан с историей возникновения проблемы, или с историей сервера. Проблема заключается в том, что человек, с которым вы разговариваете может не обладать необходимой вам информацией. Например, человек хочет вам помочь, но не знает истории сервера. Еще одно вероятное событие – человек, который вызвал вас, в действительности сделал что-то, что вызвало проблему, но слишком стесняется признать это. И тут на помощь придет монитор надежности.
Монитор надежности, изображенный на Рисунке 3, может сделать для вас пару вещей. Во-первых, вы вероятно это заметите при взгляде на рисунок – это большой график. Если вы посмотрите на верхний раздел графика, то увидите несколько точек, соединенных линией. Эти точки отображают индекс стабильности системы (system stability Index) за каждый день. Основная идея с индексом заключается в том, что значение этого индекса медленно повышается каждый день, если не было аварий и установок или удалений каких-либо приложений.
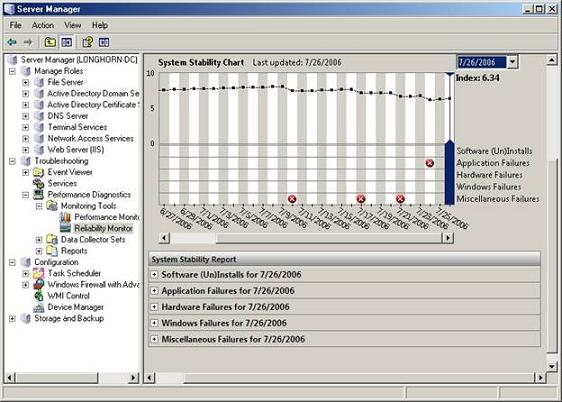
Рисунок 3: Монитор надежности отслеживает различные аварии и события, происходящие на вашем сервере
У меня нет никакой документации по монитору надежности, поэтому я ничего не могу сказать наверняка, но из того, что я имел возможность наблюдать, я могу заключить, индекс стабильности снижается после того, как вы установите приложение. Затем понемногу индекс каждый день поднимается, т.к. система подтверждает свою стабильность и после запуска этого приложения. То же самое случается и в случае аварий. При возникновении аварий, индекс стабильности резко падает на этот день. После прошествии некоторого времени индекс стабильности будет подниматься, если не будет новых аварий.
В нижней части графика вы можете увидеть, что день, в который произошла авария, отмечается на графике. Просто взглянув на график, вы можете увидеть, авария какого типа стала проблемой. Вы даже можете дважды щелкнуть на конкретной аварии, чтобы получить подробную информацию о событии, которое привело к формированию отчета об аварии.
Одна вещь, которая мне понравилась в мониторе надежности, заключается в том, что он позволяет вам предвидеть проблемы. Например, предположим, вы смотрите на график и замечаете, что при работе определенного приложения происходит сбой через каждые четыре дня. Если это происходит постоянно, то есть определенный шаблон для этого события. Шаблон очень полезен для отладки различных ситуаций. Отображение сбоев и аварий в графическом формате позволяет легко заметить шаблоны.
В этой статье я рассказал о различных инструментах для устранения неисправностей, которые встроены в менеджер сервера. Надеюсь, что после прочтения это статьи, вы начали понимать, насколько важным будет менеджер сервера в операционной системе Longhorn Server. Помните, что на момент написания этой статьи, операционная система Longhorn Server по-прежнему находилась в бета тестировании. Любой из инструментов, о которых я рассказал, потенциально может измениться к момент выхода окончательной версии операционной системы Longhorn Server.
www.windowsnetworking.com
Tags: monitoring