
Несколько месяцев назад я написал статью о многоядерных процессорах; в этой статье я упоминал о том, какие преимущества получает программное обеспечение от использования нескольких ядер. В этой статье я глубже опишу мир многопоточности, а также опишу некоторые способы снижения сложности при разработке многопоточных приложений.
Одной из технологий приложений, с которой многие из вас знакомы, по крайней мере, мимоходом, — это J2EE. J2EE – это среда, используемая во многих случаях для создания приложений уровня предприятия. Приложения, созданные с помощью технологии J2EE, легко могут использовать преимущества многоядерных процессоров. Более того, данная технология позволяет легко воспользоваться преимуществами кластеров из большого количества машин, в каждой из которых будет несколько процессоров, каждый из которых, в свою очередь, может иметь несколько ядер.
Использование J2EE для приложений предприятия позволяет разработчику писать приложение, не слишком много думая о потоках; в этом сила J2EE. Приложения J2EE делаются многопоточными изменением настроек, находящихся на сервере приложения; при этом многопоточность управляется контейнером. Как это происходит? В сущности, бизнес-логика может быть закодирована и затем размещена на сервере в логическом контейнере. Затем настройки контейнера определят, как много экземпляров определенной части бизнес-логики может быть запущено одновременно. Контейнер также определяет, сколько соединений с ресурсами (например, базами данных) можно провести одновременно. С этими свойствами, управляемыми контейнерами, иногда довольно сложно работать, но они дают возможность отделить многопоточность от самого кода приложения. Это хорошо потому, что позволяет применять многопоточность в зависимости от железа без изменения кода приложения. Замены оборудования предприятия – довольно частая вещь: к кластеры могут подключаться новые машины, могут добавляться или убираться процессоры из машин в кластере, и каждое из этих изменений влияют на возможности многопоточности приложений.
Четкое разделение логики многопоточности и бизнес-логики должно быть приоритетным для разработчиков, пишущих приложения с массовым параллелизмом. Для этого существует множество причин: простота разработки, простота отладки, а также простота внесения изменений в приложение. При разработке на C/C++ или FORTRAN’е популярным решением этой проблемы является использование OpenMP. OpenMP – это API для написания эффектного и эффективного многопоточного кода.
В сущности, OpenMP используется путем введения набора инструкций в коде в форме комментариев или аннотаций. Сначала код пишется последовательным, а затем в нужные места добавляются аннотации. А когда код компилируется после этого (OpenMP совместимым компилятором), эти аннотации учитываются, и код компилируется так, чтобы использовать потоки согласно этим аннотациям.
Когда я собирал данные для этой статьи, я столкнулся с технологией JOMP. Она аналогичная OpenMP, и может использоваться с Java. Мне неизвестно, существует ли какая-нибудь официальная взаимосвязь между JOMP и OpenMP; если кто-нибудь из читающих эту статью знает что-либо об этом, пожалуйста, отправьте мне сообщение. Мне будет очень интересно. Несмотря на то, что в Java есть встроенный API для использования и контроля потоков, применение таких решений очень полезно.
Такой метод параллельного программирования очень выгоден. Так как программа кодируется для последовательного запуска, а для распараллеливания используются всего лишь аннотации, в случае компилирования кода на обычном компиляторе он всего лишь будет их игнорировать. Этот же код можно скомпилировать и с помощью компилятора OpenMP и запустить параллельно в несколько потоков. Это означает, что разработчику не нужно будет изменять код, если программу нужно запускать на машинах с разной архитектурой: и с поддержкой многопоточности, и без такой поддержки.
Другим преимуществом OpenMP является то, что порции кода могут аннотироваться инкрементально, с очень небольшим изменением кода. Это позволяет чаще тестировать код на правильность функционирования, что важно, поскольку разработчик мог бы распараллелить многие порции кода, что затем вызвало бы различия в исполнении кода; такие случаи компилятор редко обнаруживает, и их обязательно нужно обнаруживать путем тестирования.
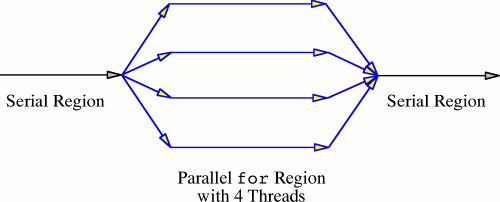
Рисунок 1:Пример многопоточного приложения. (Источник: www.acm.org)
Разработчики часто допускает одну ошибку при распараллеливании приложений, а именно при распараллеливании циклов. Например, если нужно было бы пройти по всему массиву целочисленных значений и добавить к каждому значению единицу, этот процесс можно было бы распараллелить на выполнение каждой итерации в одном потоке в одно и то же время. В OpenMP это реализовано (на C/C++) выражением #pragma omp parallel for. Но, не исключено, что кто-нибудь захочет пройти по этому же массиву и изменить его путем добавления к каждому значению значения предыдущего элемента. В таком случае было бы ошибкой распараллеливать такой цикл; если все изменения цикла производятся одновременно, вы не сможете дать гарантий того, какие именно числа будут содержаться в массиве. Запуск такого цикла в множестве потоков превратит массив в нечто совершенно отличное от того, что получилось бы в случае запуска цикла последовательно.
Еще одну ошибку иногда допускают даже опытные разработчики – ошибку с переменными, используемыми несколькими потоками одновременно. OpenMP специально используется для программ в среде с общей памятью, и, следовательно, требует от разработчиков убеждаться, что одни потоки не изменяют переменных, используемых другими потоками. К счастью, в OpenMP поддерживаются специальные выражения, которые проверяют, что этого не происходит в определенном блоке многопоточного кода. Но разработчикам все же нужно внимательно относиться к тому, чтобы использовать соответствующие аннотации при необходимости. То есть мы опять возвращаемся к осторожному и постепенному тестированию для проверки правильности работы кода при многопоточности.
При грамотной реализации многопоточные приложения могут показать значительное увеличение производительности. Конечно же, это при условии использования соответствующего аппаратного обеспечения, поддерживающего многопоточность. Но даже при соответствующем оборудовании существуют пределы увеличения производительности, которых можно достичь с помощью многопоточности. Как я уже упоминал (в примере с циклами), существуют участки кода, которые нельзя распараллеливать. Таким образом, если в программе много больших участков кода, невозможных для распараллеливания, время выполнения этих участков будет ограничивающим фактором всего времени выполнения программы. Для оценки максимально возможного увеличения производительности при распараллеливании приложения обычно используется закон Амдала.
Кроме очевидного одновременного выполнения задач при работе многопоточного приложения на многоядерных процессорах есть несколько дополнительных преимуществ. Среди них – увеличение эффективно использующейся кэш-памяти для приложения. Например, в процессоре Tile64 корпорации Tilera, описанном в моей предыдущей статье, содержится значительный логический кэш L3. Во многих случаях такое увеличение используемой кэш-памяти может значительно уменьшить время на чтение памяти, а также увеличить время выполнения.
www.windowsnetworking.com
Tags: search